Recently I had a task that sounded something like this:
Get a JS code and generate some other JS code from it.
The first part was most difficult. Info we need from code was too complex to get using regular expressions. So the search for JS parser began. It ended pretty soon when I found Esprima parser. Now I want to share my experience with it in a form of tutorial. We won’t be building code generator - I think simpler task will be enough to dive in.
What we’ll build
We will build a very simple static analyzer which will run from command line. It will warn about:
- Declared, but not called functions;
- Calls to undeclared functions;
- Functions declared multiple times.
Of course, it’s not intended for compelling with excellent JSHint or any other static analyzer. The only purpose it serves is to show you the basics of JS parsing using Esprima. The things that our analyzer will NOT do:
- Recognize any form of function declaration except:
1 2 3 | |
- Recognize any form of function call except:
1
| |
- Know something about imports, exports or predefined globals;
- Work with multiple files.
This is not the flaws of a parser. All this features can be easily implemented, they are just out of scope of tutorial.
Example will be built using NodeJS, but Esprima works also in a browser.
Preparations
I will be using node v0.8.10 and Esprima v0.9.9. Each of following commands can also be done with GUI or Windows Shell, but I’ll give examples only for Unix-like OS terminal. Create a directory for your project and install the library:
mkdir esprima-tutorial
cd esprima-tutorial
npm install esprima@0.9.9
Create a script named analyze.js with the following content:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
What happens here:
- We declare a function where we will be doing all code parsing and analysis stuff. For now its empty;
- We are checking that user passes command-line argument with a file name to analyze. Why we checking for the third argument? The answer is in node documentation:
The first element will be ‘node’, the second element will be the name of the JavaScript file. The next elements will be any additional command line arguments.
- We are reading the file content and passing it to
analyzeCode. For simplicity, I use sync version offs.readFile.
Parsing code and walking through AST
Parsing can be done with a single line of code:
1 2 3 | |
esprima.parse accepts string or node’s Buffer object. You can also pass additional options as the second
parameter to include comments, line and column numbers, tokens, etc but this is out of the scope of this tutorial.
The result of the esprima.parse code will be an abstract syntax tree (AST) of your program in
Spider Monkey Parser API format.
AST is a representation of a program code in a tree structure. For example, if we have the expression:
1
| |
AST can be graphically represented as:
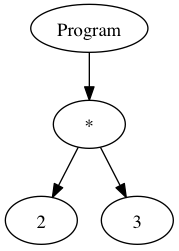
Same expression in Parser API format will look like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
The main entity of esprima.parse output is node. Each node has a type (root node is always has Program type),
0 or more properties and 0 or more subnodes. type is the only common property for nodes - names of the
other properties and subnodes depends on it.
In above example, Program has the only one subnode - body of ExpressionStatement type which too contains only
expression subnode of type BinaryExpression. BinaryExpression has property operator with value of “*” and
left and right Literal subnodes.
To be able to analyze the code we need a way to loop throught AST. Add following code before analyzeCode function:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
This function accepts root node and a function and calls it recursively for each node in a tree.
- Calling the function for a root node;
- Loop through all properties of a root a node;
- Ignore inherited properties of an object;
- Ignore simple and null properties. All nodes are actually complex objects and all properties has simple type.
Null check is necessary, because
typeof null === 'object'; - Each child can be either single subnode or array of subnodes. If its an array, we call
traverserecursively for each subnode in it. - If child is not an array, just call
traverserecurively on it.
To test the function replace analyzeCode function with the following code:
1 2 3 4 5 6 | |
When you execute you script on some JS code you should see types of all nodes in a tree.
Getting data for analysis
To do the analysis we need to loop through an AST and count number of calls and declarations for each function. So, we need to know format of two node types. The first one is function declaration and it looks like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Type of a node is FunctionDeclaration. Identifier is stored in id subnode and name of the function is in a
name property of this node. params and body contain parameters and body of the function. Rest of the node
properties is omitted.
Second node is CallExpression:
1 2 3 4 5 6 7 8 | |
callee is an object being called. We are interested only in callee with Identifier type. Few other possible
types are MemberExpression (call of the object method) and FunctionExpression (self invoking function).
Now we have all information to perform the analysis. Replace analyzeCode function with:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
- Creating a new empty object that will store calls and declarations statistics for each function. Function name will be the key of statistics entry;
- Declaring a function that will add an empty entry for the function name to the
functionStatsobject, if we haven’t done this previously; - Begin loop through the AST;
- If we found function declaration, increase declaration count;
- If we found function call by name, increase call.
Processing results
Now the final part, processing the results we gathered and reporting all found issues.
Add following function:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
I think the code is pretty self-explanatory and doesn’t need my comments.
Finally, add call to processResults to the bottom of analyzeCode function:
1
| |
Testing
Run the script on this meaningless code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
You should see something like this:
Inf:esprima-tutorial$ node analyze.js test.js
Reading test.js
Function declaredTwice decalred multiple times
Function undeclared undeclared
Function unused declared but not called
Done
Of course, if you run it on some real code you will see all the flaws we discussed at the beginning of the article. Again, point of the article is to teach how to use Esprima, not how to write static analyzers.
Conclusion
Its time to end the tutorial. We’ve learnt how to parse JS code using Esprima, the format of SpiderMonkey Parse API syntax tree. Also, we’ve learn how to traverse through AST and how to search for syntax constructions we interested in.